Powering Cutting-Edge AI Applications on a New Data Platform
Appen accelerates and scales its data transformation services for Machine Learning, and generates reports 30x faster on its new, cloud-native data platform, helping to build effective AI solutions
Appen is an AI data collection, aggregation, and cleaning company that provides high-quality training data for organizations that build effective AI systems. In 2020, Appen integrated Figure Eight, a human-in-the-loop AI/ML-powered platform for data transformation, to boost the efficiency of transforming text, images, audio, and video data into customized high-quality training data.
Challenge
Appen wanted to improve the quality and scalability of its data collection, processing, and reporting workflows by building a new data platform for real-time analytics on AWS. The platform will replace the legacy monolithic solution that was introduced in the company’s early days, to ensure faster data processing and reporting.
Solution
Provectus built a next-generation data platform with a data lake and real-time analytics capabilities. Data pipelines incorporating Apache Kafka, Amazon S3, and Amazon ECS were hooked up to the AWS Glue-based data lake and Amazon Athena for report generation. Apache Kafka was used as a central hub to handle microservices and databases.
Outcome
The data platform built by Provectus allows Appen to scale its data processing and reporting pipelines while enabling near real-time data analytics. The platform has helped Appen to accelerate data processing by 5x, increase the volume of data jobs handled per hour by 20x, and reduce the time needed to report on data by 30x.
30x
Faster analytics and data reporting
20x
Increase in number of data jobs handled per hour
5x
Increase in speed of data processing in the pipelines

Highly Scalable Data Platform Enables Real-Time Analytics and Reporting, and Serves as a Foundational Service for AI
Appen’s mission is to help organizations drive their AI/ML initiatives by providing them with high-quality training data, and to automate business processes with easy-to-deploy ML models and integrated human-in-the-loop workflows.
As part of its business expansion strategy, Appen wanted to take its data transformation services to another level. This required a new, highly scalable cloud-native data platform that could generate near real-time reports on data while serving as a foundational service for AI.
The leadership of Appen hoped that the new platform would help them to address architecture and technology limitations of the legacy monolithic solution introduced in the early days of the company, in a bid to increase the quality of data and improve the scalability of data collection, processing, and reporting services.
The envisioned data platform had to be built as:
- A highly scalable solution capable of supporting up to 1K parallel workflows for data collection, processing, and reporting
- An efficient analytics solution that enables data annotation teams and business units to generate data reports in real time
- A solution with advanced architecture, with the support of microservices and specific ML models as part of its data processing workflows
Appen teamed up with Provectus to develop its solution on AWS. The teams opted to use Provectus’ NextGen Data Platform as a foundation for the Appen solution, and to fine-tune it through a series of Appen-specific customizations.

Building a Next-Generation Data Platform with a Data Lake and Advanced Real-Time Analytics Capabilities
Provectus began designing and building a new data platform for Appen by conducting a series of discovery workshops, to assess the current state of operations, infrastructure, and architecture of Appen’s applications, and to identify business KPIs for the platform.
At this stage, Provectus discovered several architectural and infrastructural limitations of Appen’s existing legacy monolithic solution, which prevented its data annotation and analytics teams from processing data on a larger scale and generating reports in real time. Those limitations increased overhead and inefficiencies, and the total cost of ownership (including the cost of service for Appen’s clients), and slowed down Appen’s data expansion for the AI market.
Provectus proposed building a new data platform on AWS, with a data lake and advanced capabilities for near real-time analytics and report generation. The architectural diagram is detailed below.
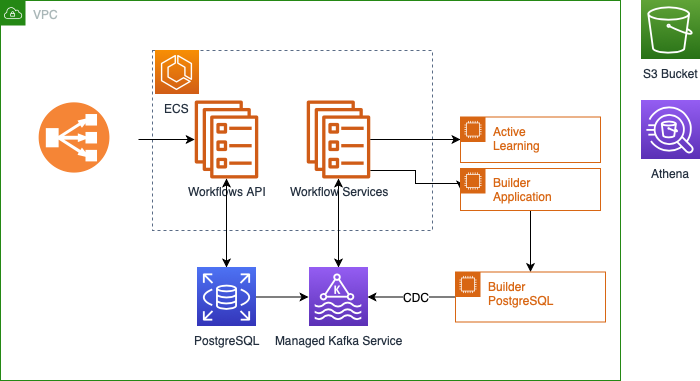
The engineering team designed and built scalable data pipelines on Apache Kafka, Amazon S3, and Amazon ECS. Appen’s non-relational data streams and workloads were migrated to these new data pipelines, once they were tested and fine-tuned.
Provectus used AWS Glue, Amazon Athena, and Amazon S3 to build a new cloud-native data lake for Appen. We took advantage of the flexibility, scalability, and efficiency of AWS services to ensure that the teams at Appen could handle data faster and on a larger scale.
To meet Appen’s scalability requirements, we split its monolithic data workflows into specific microservices, powered by Kafka Streams. Apache Kafka served as a central hub for communication between various microservices and databases. As part of the migration strategy, we also used the Use Change Data Capture (CDC) mechanism from PostgreSQL as the initial data feed for consuming microservices.
The initial testing of the proposed solution demonstrated linear scalability and significant performance improvements.

Faster, More Efficient Data Processing and Analytics Drive Efficiencies and Accelerate Appen’s Business Expansion
Appen’s potential to grow its business was limited by the outdated technologies used to power its data services. The company provided high-quality training data to its clients but lacked the tools to accelerate and scale data transformations.
Provectus helped Appen to overcome its technology barriers and enabled it to reduce overhead costs, drive operational efficiencies, and speed up business growth.
We drew from our expertise in developing state-of-the-art streaming data platforms to build a new, highly scalable cloud-native data platform with a data lake and advanced real-time analytics capabilities for Appen.
The new data platform has enabled Appen to accelerate and scale its data transformation services, while providing its teams with powerful tools for near real-time data analytics and reporting.
Now, Appen’s end-to-end data pipelines operate five times faster, while the throughput of data annotation jobs and data rows has increased by 20 times. The time needed to generate a report on processed data has been reduced from almost 30 minutes to less than a minute. These results are possible thanks to the advanced architecture of the data platform, which ensures linear scalability and significant performance improvements.
By using the new data platform delivered by Provectus, Appen can transform any type of data quickly and at scale. The platform provides a solid foundation for Appen’s growth and expansion of data for the AI market.
Moving Forward
- Learn more about the Provectus Nextgen Data Platform
- Explore more customer success stories covering data platforms: Swiftmile, Second Genome, IMVU, TripActions
- Apply for NextGen Data Platform Acceleration Program, to get started
Contact Us!
Looking to explore the solution?
.png)