Machine Learning Operations (MLOps)
Deliver ML models from research to production faster and with minimal handoff at scale, to accelerate time-to-value for AI initiatives.
Contact usThe radical shift from model building to real-world ML consumption naturally leads to MLOps
The market for AI is changing. The focus has shifted from companies that have the technical expertise to build models, to enterprises that use AI solutions powered by those models. Model development is no longer the key focus, but an integral part of the process of deployment, maintenance, and governance of models. MLOps is a practice that helps manage development, usage, operationalization, and deployment of models in production. It evolved to streamline the working relationship between data scientists who build models and IT Ops who operate solutions powered by these models, to drive AI initiatives.
What Is MLOps?
MLOps, or Machine Learning Operations, is a set of practices for smooth collaboration and communication between data scientists and operations professionals, to help manage the ML production lifecycle and enable businesses to run AI successfully.
- Work with data
- Build ML models
- Use a variety of tools, languages, and platforms
- Ensure production safety
- Follow policy and processes
- Operate and manage the solution
- Want positive results
- Wish to avoid biases
- Need a trustworthy solution for their companies and customers
Benefits of MLOps
Rapid innovation through robust ML lifecycle management
Repeatable workflows allow for automatic streamlined changes
Reduced friction between data science and operations teams
Easy deployment of ML models thanks to automatic scaling
Better governance and compliance through model reproducibility
Improved model monitoring to detect anomalies
Enabling AI Adoption at Scale
ML innovation requires extensive experimentation with different features, algorithms, model types, parameters, and configurations. Every experiment must be tracked, and its results must be saved, to maintain reproducibility, maximize code reusability, and accelerate time to value.
Software testing is a streamlined process that has improved over the years. ML system testing is not that simple. Data must be properly checked and validated. Trained ML models need to be tested and their quality evaluated on a testing dataset. Finally, an ML model has to be validated before deployment.
ML models cannot be treated like code by IT teams. Instead of deploying models as a service, they have to deploy a multi-step pipeline for automated model retraining and deployment. Every step completed by data scientists prior to deployment must be automated, to ensure efficiency of model training and validation.
Traditional software tools cannot track ML model behavior. Monitoring is key, since not only code but also constantly evolving data can affect models' performance. Data statistics must be tracked, and performance must be monitored to ensure timely notifications and roll back, in case of quality deviations.
ML models have a complex lifecycle. To maintain required performance and accuracy, they need to be frequently updated. Model management allows us to keep track of model use context, and to re-deploy models when they show signs of data drift, concept drift, or any other signs of performance deterioration.
Governance of ML models in production allows us to minimize risk, and ensures compliance with regulations. It also allows us to keep track of changes, making it easier to improve the models and the process of rapid, easily scalable deployment and management of ML applications in production environments.
The Core of MLOps and Reproducible Experimentation Pipelines
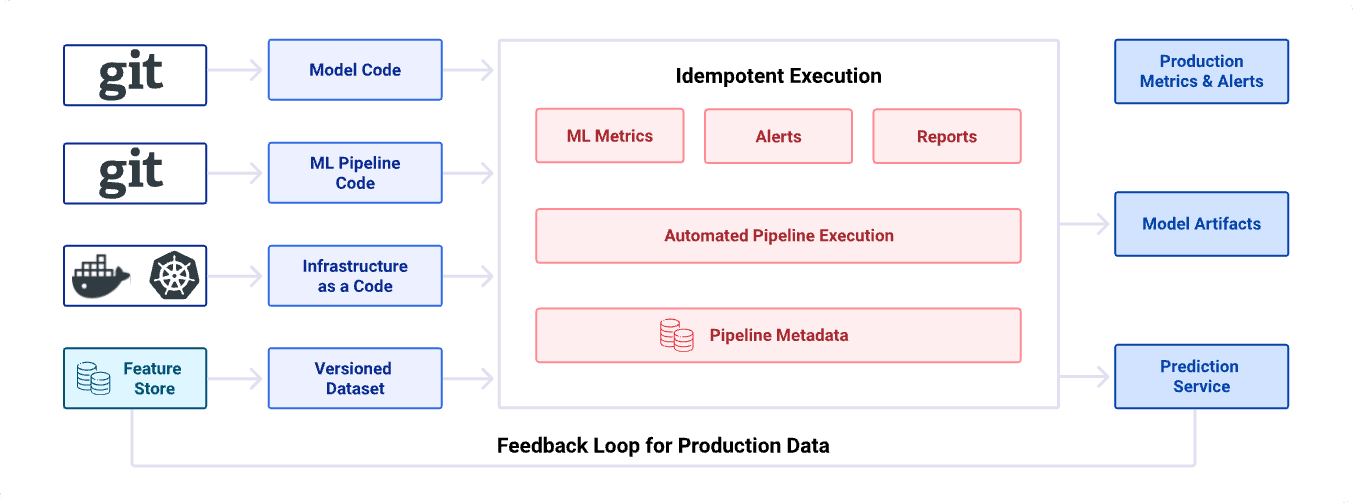
The code of an ML model, ML pipeline, infrastructure, and dependencies (all of which are stored and versioned in Git), as well as a dataset from a centralized Feature Store, are compiled into the model by ML Orchestrator, to generate logs, metrics, alerts, and data for storage and analysis. Continuous Delivery and Experimentation workflows are dynamically integrated, allowing us to use the same pipeline to trigger experiments manually and automatically, triggered from Git hook & CI/CD tools for continuous integration and deployment.
We Follow MLOps Best Practices
- 01
Create models with reusable ML pipelines, with code being automatically integrated into the MLOps pipeline
- 02
Automate MLOps rollout using services for DevOps and Machine Learning to manage data, version models, handle events, etc.
- 03
Create an automated audit trail to ensure that all artifacts in the MLOps pipeline can be checked for integrity and compliance
- 04
Deploy models and monitor their performance using dashboards and alerts, to know when to roll back and re-deploy models
- 05
Observe data concept drifts, and use collected feedback to retrain models and improve their performance
Start your AI/ML implementation journey with Provectus
